이 글에서는 기본적인 Application 서비스 환경에서 대규모 서비스로의 전환을 시간 순으로 나열해보겠습니다.
현재 시스템 구성
현재 서비스는 1개의 Nginx 웹 서버와 2개의 Tomcat 애플리케이션 서버로 구성되어 있습니다.
기존

요청의 흐름
- 사용자는 로컬 또는 DNS 서버를 통해 IP를 받아와 HTTPS(443 포트)로 요청을 보냅니다.
- 요청은 웹 서버를 거쳐 애플리케이션 서버로 전달되고, 필요한 경우 데이터베이스(DB)에서 데이터를 가져와 사용자에게 응답을 전송합니다.
- HTTP 요청과 응답 구조를 따릅니다.
대규모 서비스 전환 단계
이제 각 컴포넌트의 성능을 높이고 트래픽을 효과적으로 분산하기 위해 시스템을 확장하는 단계를 살펴보겠습니다.
1. Database 의 Scale Up
현재 DB 성능이 충분하지 않다면, Scale Up을 통해 처리 성능을 높입니다.
- 물리 서버 환경: DB를 중단하고 백업을 수행한 후, 더 높은 사양의 서버로 데이터를 이전합니다.
- 컨테이너 환경: 컨테이너 설정에서 리소스를 재할당한 후, DB 컨테이너를 재시작하여 적용합니다.
2. Application Server의 Scale Out
대량의 요청이 들어오면, 연산 작업이 집중되는 애플리케이션 서버(Tomcat) 에서 CPU나 메모리 사용량이 급증할 수 있습니다.
Scale Out을 통해 서버 대수를 늘려 부하를 분산시킵니다.
- Tomcat 서버 추가: Tomcat 서버를 2대 더 추가하여 총 x대의 애플리케이션 서버로 구성합니다.
- Nginx 업스트림 설정: Nginx의 upstream 설정을 통해 x대의 서버에 트래픽을 분산하도록 구성합니다.
- 세션 관리: 세션을 공유해야 한다면, Redis 서버를 클러스터링 하거나 새로운 Redis 서버를 추가하여 모든 Tomcat 서버에서 세션을 공유할 수 있게 설정합니다.
오토스케일링 옵션 또는 컨테이너 오케스트레이션(Kubernetes)를 통한 확장 방법도 있습니다.
3. Load Balancer
트래픽이 점차 증가하여 10만, 100만 단위까지 올라갈 경우, 웹 서버도 과부하될 수 있습니다. 로드 밸런서를 도입하여 서버 부하를 최소화하고 확장성을 확보합니다.
- 트래픽 부하 분산: 로드 밸런서를 추가하면 모든 애플리케이션 서버에 균등하게 트래픽이 분산되어, 서버 과부하를 방지하고 응답 시간 및 안정성을 높일 수 있습니다.
- 확장성: 로드 밸런서를 통해 트래픽 변화에 따라 애플리케이션 서버(WAS)의 대수를 유동적으로 조정할 수 있습니다.
- 고가용성(HA): 로드 밸런서는 서버 상태를 지속적으로 모니터링하여 장애가 발생한 서버를 자동으로 제외하는 Failover 기능을 제공하며, 복구된 서버를 다시 포함시키는 FailBack 기능도 지원합니다.
대체 방안: 전용 로드 밸런서 장비가 없다면, Nginx의 소프트웨어 로드 밸런싱 기능을 사용할 수 있습니다.
Nginx는 소프트웨어 로드 밸런서로서 비용 효율적인 대안이지만, 트래픽이 매우 높은 경우 전용 하드웨어 로드 밸런서에 비해 성능이 제한될 수 있습니다.
4. Database Replication DB 부하분산
요청량이 100만 단위를 넘어서면, 단일 DB 서버에 과도한 부하가 발생할 수 있습니다. 이 경우 Replication 아키텍처를 통해 트래픽을 분산할 수 있습니다.
필요에 따라서 구성을 달리 할 수 있는데 아래 이미지는 읽기 작업이 많은 경우의 Replication 아키텍처의 구성입니다.
Replication 아키텍처: Master-Slave 구조를 사용하여 트래픽을 분산합니다.
- Master DB: 데이터의 Insert, Update, Delete 작업을 처리
- Slave DB: 읽기 작업을 처리하여 읽기 부하를 분산
- 한계점: Replication은 읽기 부하를 분산하는 데 효과적이지만, 쓰기 작업은 여전히 Master DB에 집중됩니다. Master DB에 과부하가 발생하면 지연(Lag)이 생길 수 있어, 추가 확장 방안을 고려해야 합니다.
5. Multi 구조의 Replication 과 Caching
자주 조회되는 데이터나 복잡한 쿼리에 대해 반복적인 요청이 발생할 경우 캐싱(Cache)을 통해 데이터베이스 부하를 분산할 수 있습니다.
DB에서의 캐시와 Application의 캐시 중 선택하여 적용할 수 있습니다.
- 쿼리 캐싱: 동일한 쿼리가 반복적으로 실행될 때 결과를 캐싱하여 빠르게 반환합니다.
- 애플리케이션 캐싱: Redis, Memcached, Ehcache 등과 같은 캐시 솔루션을 사용하여 애플리케이션에서 자주 조회되는 데이터를 캐싱할 수 있습니다.
- 주의사항: Redis와 같은 외부 캐시를 사용할 경우, 별도의 서버 증설과 모니터링이 필요하므로 추가적인 관리 비용이 발생할 수 있습니다.
애플리케이션 캐싱 전략(유저 프로필을 업데이트 할 경우)
- 만약 유저 프로필을 업데이트 한다고 했을 때 invalidate cache를 호출합니다.
- Database에 업데이트 하고 Cache에 input 합니다.
- Read Hit 비율이 높아지면, 데이터베이스 요청을 줄여 효율적으로 리소스를 관리할 수 있습니다.
invalidate cache 전략으로 직접 삭제 뿐 아니라 TTL(Time-To-Live) 설정과 LRU(Least Recently Used) 방식 등이 있습니다.
대표적인 애플리케이션 캐시 라이브러리는 Ehcache, Redis(Jedis, Lettuce), Memcached 등이 있습니다.
6. 비동기 아키텍처 구성
100만 건 이상의 대량 요청이 발생하면 시스템에 병목이 생기기 시작합니다. 특히 쓰기 작업이 많은 경우, 비동기 아키텍처를 통해 성능을 최적화할 수 있습니다.
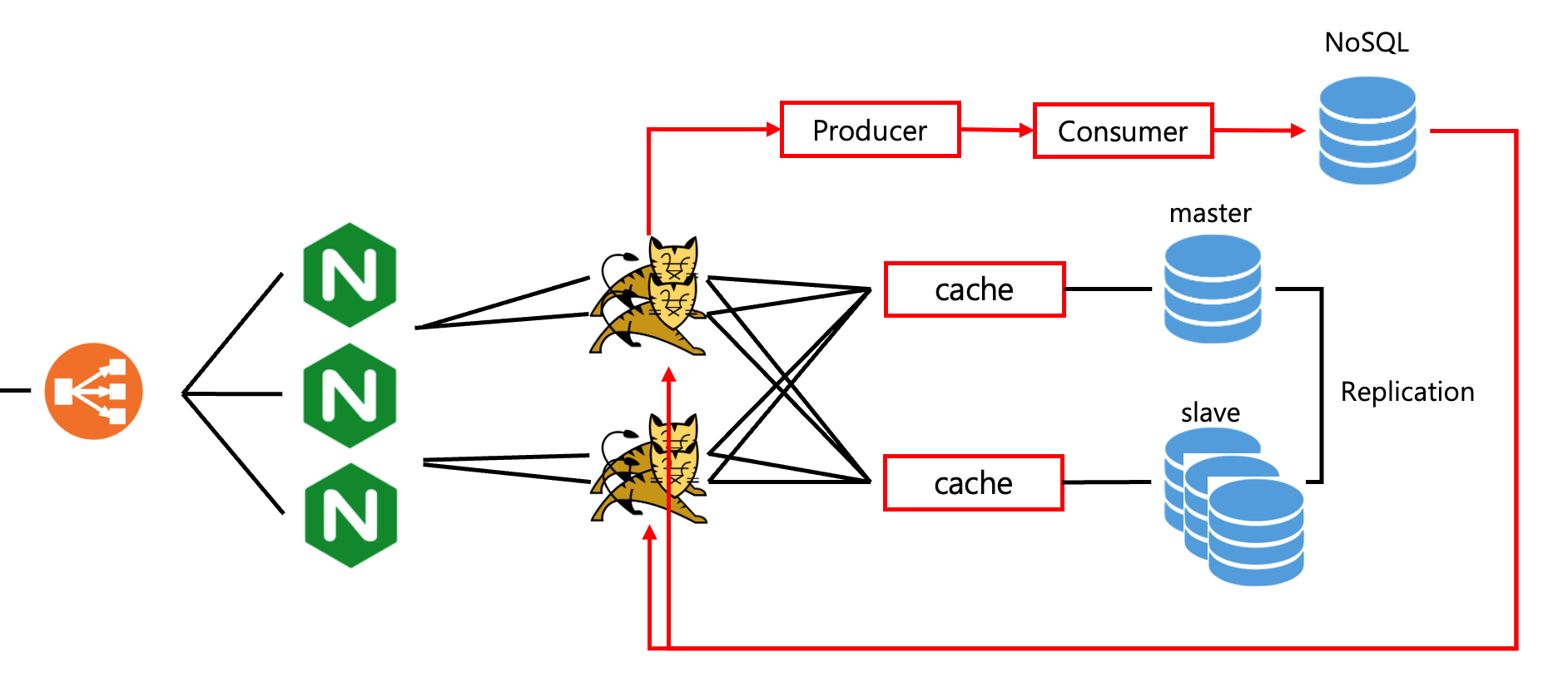
비동기 처리 방식(쓰기가 많은 경우에 유효한 전략입니다.)
- 비동기로 처리할 수 있는 작업에 대해서는 Producer를 앞단에 배치하여, 비즈니스 로직과 별개로 작업을 분리합니다.
- Consumer(Worker)는 필요한 데이터를 MQ(Kafka 등)에서 받아와 백엔드 DB 또는 NoSQL에 쓰기 작업을 수행합니다
- 이러한 비동기 방식은 메인 비즈니스 흐름에 영향을 주지 않으며, 대량 쓰기 작업이 병목을 일으키지 않도록 효율적으로 처리합니다.
7. 이외의 고려사항
비동기 아키텍처 외에도 다음과 같은 확장 전략을 고려할 수 있습니다.
- 샤딩(Sharding): 월 1억 건 이상의 데이터가 누적되는 경우, 파티셔닝과 샤딩을 통한 DB분산을 고려해야 합니다.
- RDB 샤딩: 샤딩 키 전략과 DB 추가 시 데이터 마이그레이션 전략 및 트랜잭션 관리가 검토에 포함됩니다. (또한 복잡한 쿼리문은 사용이 어려우며, 오히려 샤딩의 성능이 안나올 수 있습니다.)
- NoSQL 샤딩: RDB보다 비교적 구성이 단순하며, 대부분의 NoSQL 데이터베이스는 샤딩을 기본 기능으로 지원합니다.
- 클라우드와 CDN: 클라우드 환경에서 Kubernetes를 사용한 분산 및 확장, 컨텐츠 캐싱을 위한 CDN 도입도 고려할 수 있습니다.
- 멀티 마스터-멀티 슬레이브: 데이터가 폭발적으로 증가하는 경우, 멀티 마스터-멀티 슬레이브 아키텍처를 구축하여 병렬 쓰기 작업을 분산하여 성능을 극대화 할 수 있습니다.
- MSA(Microservices Architecture): 데이터 처리량이 계속해서 증가한다면 MSA를 도입하여, 서비스 단위로 독립적인 확장성을 확보할 수 있습니다.
이와 같은 다양한 아키텍처 확장 방안을 통해 각 서비스의 특성과 요구사항에 맞춘 유연한 시스템 구성이 가능합니다.
트래픽 증가와 대규모 데이터 처리에 효과적으로 대응하면서, 안정성, 확장성, 성능을 극대화할 수 있습니다.
'Architecture' 카테고리의 다른 글
| 소프트웨어 복잡성 (0) | 2025.03.29 |
|---|---|
| 코어 수에 따른 프로세스와 쓰레드 개수의 관계와 성능 영향 (1) | 2024.11.04 |
| CachedThreadPool의 한계와 ThreadPoolExecutor 커스터마이징 (1) | 2024.10.28 |
| 의존성 역전 원칙(DIP): 유연하고 확장 가능한 코드 설계의 핵심 (0) | 2024.02.05 |
| 좋은 코드를 위한 5가지 핵심 원칙: SOLID부터 리팩토링까지 (0) | 2024.01.21 |
