
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 동시성제어
- JPA
- spring boot
- jvm
- 백엔드
- webflux
- monitoring
- kafka
- DevOps
- GitOps
- 트랜잭션
- grafana
- RDBMS
- NIO
- netty
- mysql
- SpringBoot
- prometheus
- selector
- Kubernetes
- helm
- Java
- redis
- 성능 최적화
- 성능최적화
- 백엔드개발
- CloudNative
- Kotlin
- docker
- 데이터베이스
- Today
- Total
유성
ELK 스택으로 실시간 로그 수집 및 분석하기: Logback, Filebeat, Elasticsearch, Kibana Quick Starter 본문
ELK 스택으로 실시간 로그 수집 및 분석하기: Logback, Filebeat, Elasticsearch, Kibana Quick Starter
백엔드 유성 2024. 8. 18. 14:23서비스를 운영하고 모니터링 하기 위해서 로그 수집은 중요하죠.
ELK 스택의 간단한 소개와 사용 방법에 대하여 소개하겠습니다.
우선 로그를 분석하기 위해서는 DB에 쌓여있는 로그가 있어야겠죠.
로그를 수집하기 위해서 아래 것들을 사용할 겁니다.
1. 로그 저장 라이브러리 : logback
2. 파일로 저장된 로그를 읽어서 네트워크로 로그를 전송하는 프로그램 : filebeat
3. 전송받은 로그를 저장하는 프로그램 : elasticsearch
4. 로그를 보기쉽게 정렬하고 분석해주는 프로그램 : kibana
로그 저장 라이브러리 [Logback]
log4j, slf4j 와 logback 등 여러가지 라이브러리가 있으나,
spring boot 1.0.0 버전부터 spring boot starter에 포함된 logback을 사용하겠습니다.
저는 spring boot 3.3.2를 쓰고있기에 application.yml을 수정했습니다.
logging:
file:
name: /Users/yuseonghyeon/workspace/log-center/logs/log-center.log
path: /Users/yuseonghyeon/workspace/log-center/logs
pattern:
file: >
{"timestamp":"%d{yyyy-MM-dd'T'HH:mm:ss.SSSXXX}",
"level":"%p",
"thread":"%t",
"logger":"%c",
"message":"%m",
"method":"%M",
"line":"%L",
"exception":"%ex"}
이렇게 수정하고 application을 실행시키면 logging.file.name 이라는 곳에 파일이 생성됩니다. 데이터는 pattern과 같이 생성됩니다.
로그를 저장하는 내용을 봤으니 이제 파일을 읽어서 전송하는 프로그램을 보겠습니다.
파일로 저장된 로그를 읽어 네트워크로 전송해주는 프로그램 [FileBeat]
filebeat를 로그 수집에 대중적으로 사용중인데 그 이유는 매우 경량화된 프로그램이고, spring, java 뿐 아니라 apache, nginx 등 다양한 입력 소스를 지원하기 때문입니다.
저는 docker-compose로 설치하고 실행하겠습니다. elastic, logstash, kibana, filebeat 순서로 적어놓았습니다.
elasticsearch:
image: elasticsearch:8.10.2
container_name: elasticsearch
environment:
- discovery.type=single-node
- xpack.security.enabled=false
- xpack.security.transport.ssl.enabled=false
- xpack.security.http.ssl.enabled=false
- ES_JAVA_OPTS=-Xms1g -Xmx1g # 메모리 설정
ports:
- "9200:9200"
- "9300:9300"
volumes:
- es-data:/usr/share/elasticsearch/data
logstash:
image: docker.elastic.co/logstash/logstash:8.10.2
container_name: logstash
ports:
- "5044:5044"
volumes:
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf
depends_on:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.10.2
container_name: kibana
environment:
- xpack.encryptedSavedObjects.encryptionKey=some_long_random_string_for_encryption_key_123
ports:
- "5601:5601"
depends_on:
- elasticsearch
filebeat:
image: docker.elastic.co/beats/filebeat:8.10.1
container_name: filebeat
user: root
volumes:
- ./filebeat.yml:/usr/share/filebeat/filebeat.yml
- ./logs:/usr/share/filebeat/logs
depends_on:
- elasticsearch
- logstash
- kibana
volumes:
es-data:
docker-compose.yml 파일을 실행시키는 위치에서 filebeat.yml 을 만들어 파일비트 설정을 해주셔야 하는데요.
저는 아래와 같이 수정했고, 중요하게 보셔야 할 부분은 filebeat input paths와 ouput elasticsearch 입니다.
filebeat inputs paths는 로그 파일이 저장되는 경로이여야 하며, 해당 위치 이름으로 로그파일이 생성되어야 합니다.
output elasticsearch는 아래 다시 설명하겠으나, elastic이 올라가있는 host와 port를 입력해야 합니다.
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/share/filebeat/logs/log-center.log
json:
keys_under_root: true
overwrite_keys: true
fields:
app_name: log-center
environment: production
output.elasticsearch:
hosts: ["http://elasticsearch:9200"]
#output.logstash:
# hosts: ["logstash:5044"]
setup.kibana:
host: "http://kibana:5601"
전송받은 로그를 저장하는 프로그램 [ElasticSearch]
이제 전송된 로그를 받아 저장해야겠죠. ElasticSearch는 검색 엔진 기반의 분산 NoSQL 데이터베이스로
로그를 분석하기 좋은 DB입니다.
위에 적어놓은 docker-compose.yml로 elastic search를 설치하시거나 직접 설치하셔도 됩니다.
이제 Filebeat와 Elastic Search를 연동해야 합니다.
filebeat.yml 설정파일에 다음과 같이 host와 port를 명시해줍니다. 저는 elasticsearch container에 5044포트로 설정했으므로 다음과 같이 설정했습니다.
output.elasticsearch:
hosts: ["http://elasticsearch:9200"]
이제 spring boot 프로젝트와, filebeat, elastic search를 켜주세요.
그리고 http://localhost:9200/_cat/indices?v 를 들어갔을 때 index가 생성되었는 확인해주세요.
만약 생성이 안되었다면, filebeat.yml에서 설정한 로그 경로에 로그가 있는지 확인해주시고, elastic search 서버 설정이 어떻게 되어있는지도 확인해주세요.
만약 index가 filebeat 이름으로 생성되었다면, kibana를 설치/실행 시켜주시면 됩니다.
http://localhost:5601/app/home#/
kibana에 들어가서
discover 쪽으로 이동합니다.
http://localhost:5601/app/discover#/

discover에서 왼쪽 위 filter 기능이 있는데 filebeat 에서 온 데이터만 필터링 하기 위해서
'Create a data view'를 클릭하고
> name : filebeat
> index pattern : filebeat-*
를 입력하신 다음에 다시 discover을 보면
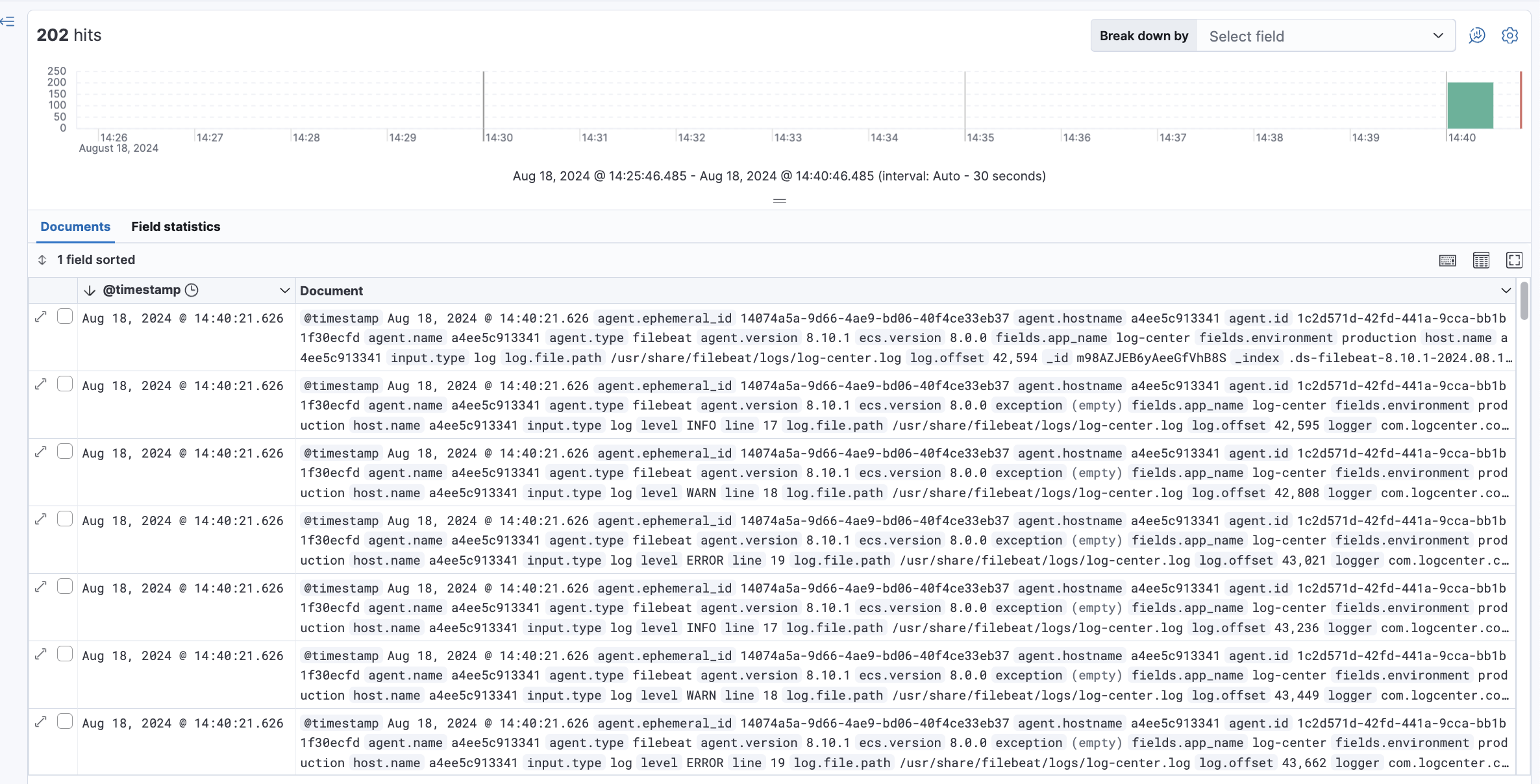
file로 저장된 로그들에 대해서 이렇게 몇분에 어떻게 나온 로그인지 확인할 수 있습니다.
여기서 level : "ERROR" 로 검색을 하면 ERROR 로그리가 몇시에 몇번 찍혔는지 확인할 수 잇습니다.
추가로
로그에 대한 필터링이 필요하면 필터링 기능을 추가할 수 있는 logstash
그리고 서비스 다운을 대비해 안정성을 높힐 수 있는 kafka
를 추가하여 서비스 를 구성할 수 있습니다.
예) Filebeat > Kafka > Logstash -> ElasticSearch > Kibana
감사합니다.
'DevOps' 카테고리의 다른 글
| Linux Page Cache와 Linux OS의 메모리 사용 전략 (0) | 2025.12.09 |
|---|---|
| 랜섬웨어 공격 경험 기록: Docker 설정이 만든 보안 구멍 (1) | 2025.08.21 |
| Grafana로 실시간 서비스 모니터링: Actuator와 Prometheus Quick Starter (0) | 2024.08.15 |
| Kafka의 EOS 보장 및 성능 최적화 전략: Producer, Consumer, Broker 설정 (1) | 2023.08.08 |
| 반복적인 일을 자동화하자!! .1부 (시스템 점검 자동화) (0) | 2023.04.01 |

