시스템이 성장함에 따라 단일 DB에서는 성능에 저하 또는 장애가 발생할 수 있습니다.
이때 DB 구성 방식으로써 해결할 수 있는 방법을 순서대로 설명하겠습니다.
* Scale Up
첫 번째로 고려할 방법은 "스케일 업"입니다. 이는 기존의 컴퓨터 하드웨어(CPU, RAM, Disk 등)를 더 강력한 것으로 교체하는 방식으로, 기존의 애플리케이션 코드나 데이터베이스 구조를 크게 변경하지 않아도 됩니다.
스케일 업은 초기 단계에 고려되는 이유는 기존 DB를 그대로 사용할 수 있으므로 하드웨어 리소스를 제외한 추가 비용이 들지 않기 때문입니다.
그러나 Scale Up에는 한계가 있고, 시스템이 더 커진다면 다음 방법을 고려해야 합니다.
* Scale Out
다음으로 고려할 방법은 "스케일 아웃"입니다. 이는 데이터베이스 서버를 추가로 배치하여 성능을 향상시키는 방법입니다. 하지만 서버를 추가하면 어떤 데이터를 어디에 저장해야 하는지에 대한 문제가 발생합니다. 이에 대한 해결책은 다음과 같습니다.
1. Reflection

동일한 데이터를 여러 데이터베이스 서버에 복제하는 방법입니다. 일반적으로 한 서버는 쓰기 작업을 처리하고 (Master), 나머지 서버는 읽기 작업을 처리합니다 (Slave). 이 방법은 읽기 작업의 성능을 크게 향상시킬 수 있지만 쓰기 성능에는 큰 영향을 주지 않습니다. 데이터 리플리케이션 과정 중에 발생하는 네트워크 및 I/O를 고려하여 설계해야 하며, 모든 데이터를 모두 옮기기에는 오버헤드가 너무 크다면 최근 변경된 데이터만 복제하는 "증분 리플리케이션"을 고려해볼 수 있습니다.
2. Data Replication
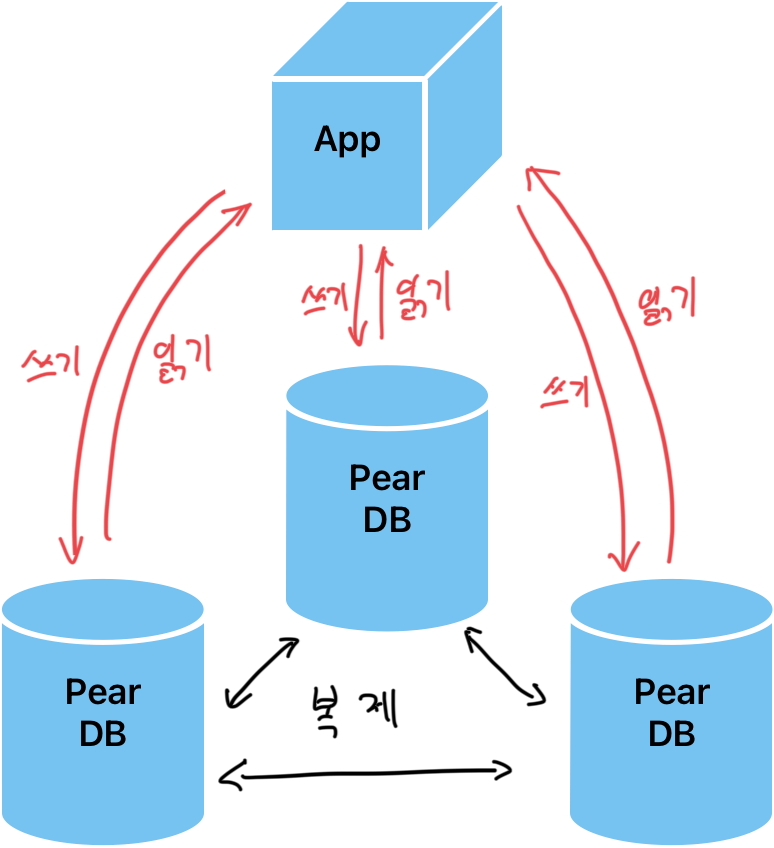
데이터 복제는 리플리케이션과 유사한 개념이나 약간의 차이가 있습니다. 리플리케이션은 Master - Slave 관계로 DB를 구성했다면, 데이터 복제는 Peer - Peer 방식으로 DB를 구성합니다. 모든 노드는 모두 읽기/쓰기를 지원하며, 쓰기 작업을 한 데이터만 서로 복제하는 방식입니다. 이 방식은 하나의 DB에 장애가 나더라도 서비스 중단 없이 운영이 가능하며 "내결함성"을 높힐 수 있는 방법입니다.
또한 한국과 미국에 서비스하는 DB라면 노드를 한국과 미국에 설치해 지연 시간을 줄일 수 있습니다.
3. Sharding

데이터를 분산 저장하는 방법으로 쓰기 성능을 크게 향상시킬 수 있는 좋은 방법이지만 구현이 쉽지 않습니다. 예를 들어, DB 2대가 있고 기본 키(pk)가 홀수인 값은 1번 DB로, 짝수인 값은 2번 DB로 할당한다고 가정해봅시다. 서비스가 더 성장해서 DB가 추가되면 데이터 재배치 과정과 함께 데이터 분할 전략을 다시 짜야 합니다.
또한 1, 2, 3번의 데이터가 각각 1, 2, 3번의 DB에 존재한다면 한번의 트랜젝션으로 데이터를 가져올 수 없으므로, 분산 트랜잭션 처리 메커니즘을 만들어야 합니다.
이처럼 샤딩은 구현하기 어려운 분산 저장 방법이지만 잘 활용하면 대규모 시스템에 아주 적합합니다.
4. DB Clustering
DB 클러스터링은 여러 대의 데이터베이스 서버를 하나의 논리적인 단위로 구성하여 높은 가용성, 확장성, 성능을 제공하는 기술입니다. DB 클러스터링에는 "Shared-Everything 아키텍처"와 "Shared-Nothing 아키텍처" 두 가지 주요 방식이 있습니다.
- Shared-Everything 아키텍처
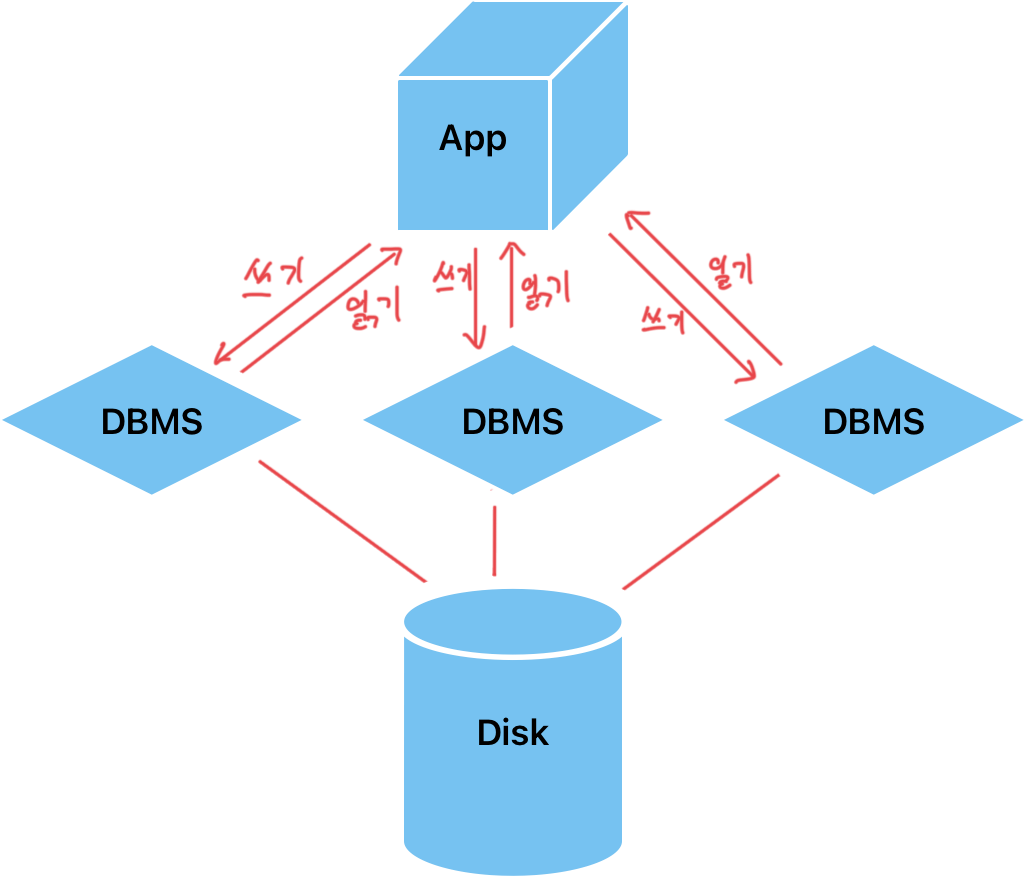
Shared-Everything 아키텍처는 하나의 공유 디스크에 여러 개의 DBMS 인스턴스가 접근하는 방식을 가리킵니다. 이 방식에서는 모든 DBMS 인스턴스가 동시에 읽기와 쓰기 작업을 처리할 수 있으므로 성능이 좋을 수 있습니다. 그러나 동시성 문제나 공유 디스크의 병목 현상이 발생할 수 있어서, 대규모 시스템에서는 확장성에 제한이 있을 수 있습니다.
- Shared-Nothing 아키텍처
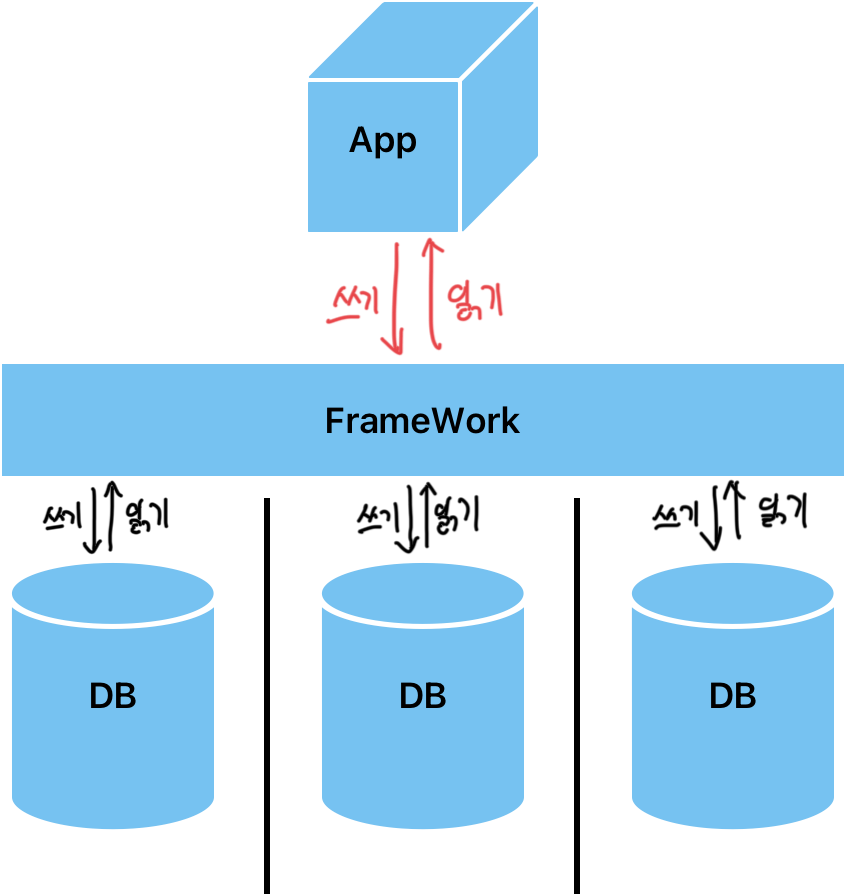
Shared-Nothing 아키텍처는 개별 디스크를 가지고 있는 독립적인 DBMS 인스턴스들로 구성되며, 각 인스턴스는 자체적으로 데이터를 관리합니다. 이 방식은 샤딩과 유사한 개념으로, 데이터를 분산해서 처리하므로 확장성이 우수합니다. 프레임워크 수준에서 데이터의 분산을 관리하기 때문에 코드 수준에서 샤딩 처리에 대한 로직을 작성하지 않아도 됩니다.
일반적으로 분산 데이터베이스 시스템을 구현하는 데에 사용되는 기술이며, 대규모 시스템에 최적화된 아키텍처입니다.
Apache Hadoop, Google's Bigtable, Amazon's DynamoDB와 같은 프레임워크가 이 방식을 지원합니다.
이 외에 아키텍처 수준에서는 마이크로 서비스 아키텍처
코드 수준에서는 캐싱과 쿼리 튜닝
DB 수준에서는 NewSQL 및 데이터 파티셔닝 등의 기술이 있습니다.
감사합니다.
'Architecture' 카테고리의 다른 글
| 효율적인 데이터 분산 저장 전략: 샤딩과 리밸런싱의 이해 (0) | 2023.08.11 |
|---|---|
| Kafka의 고가용성: 장애 대응 및 데이터 손실 방지 (0) | 2023.08.08 |
| 메시지 기반 아키텍처: 디커플링, 확장성, 높은 가용성 및 비동기 통신 (0) | 2023.08.01 |
| 자바 빌더 패턴: 객체 생성 (0) | 2023.07.22 |
| 자바 데코레이터 패턴과 람다 예외 처리: 코드 가독성을 높이는 방법 (1) | 2023.07.14 |