
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- selector
- 트랜잭션
- 동시성제어
- grafana
- kafka
- helm
- Kubernetes
- 성능 최적화
- SpringBoot
- RDBMS
- webflux
- prometheus
- JPA
- docker
- NIO
- 데이터베이스
- 성능최적화
- Java
- spring boot
- monitoring
- 백엔드
- 백엔드개발
- CloudNative
- Kotlin
- jvm
- mysql
- DevOps
- netty
- redis
- GitOps
- Today
- Total
유성
IntelliJ Profiler로 보는 JVM 힙 & 스레드 덤프로 장애 상황 분석 본문
지표가 "서버가 아프다"는 신호를 보내는 경고등이라면, 덤프(Dump)는 "진짜 범인이 누구인지" 지목하는 결정적인 블랙박스 증거이다.
장애 분석의 핵심 단계인 덤프를 통해 구체적으로 무엇을 파악할 수 있을까에 대하여, 이번 글에서는 힙 덤프와 스레드 덤프를 직접 뜯어보며, 장애의 실마리를 찾는 과정을 공유한다.
분석 도구: Intellij Profiler
과거 덤프 분석을 위해 Eclipse MAT(Memeory Analyzer Tool)을 많이 사용했지만, 최근에는 개발 환경과의 통합성이 높고 시각화가 뛰어난 Intelllij Profiler를 (필자가) 선호한다.
이번 글에서는 모든 분석 과정 역시 Intellij Profiler를 기준으로 진행해본다.
1. 힙 덤프(Heap Dump): 메모리 속 '범인'의 지문 찾기
힙 덤프는 특정 시점의 JVM 메모리 상태를 그대로 기록한 정적인 스냅샷이다.
실시간 흐름을 파악하는 프로파일링과 달리, 멈춰 있는 데이터들 사이에서 '어떤 객체가 메모리를 붙들고 있는가'를 찾아내는 것이 분석의 핵심이 된다.
실제 분석을 위해 Spring Boot 환경에서 장애를 유도하는 두 가지 케이스의 코드를 작성했다.
A. 메모리 과사용 (Memory Overuse)
객체가 의도치 않게 긴 생명주기를 가진 컨렉션에 계속 쌓이는 케이스이다.
private final List<String> items = new ArrayList<>();
@GetMapping("/add-items")
public void addItems() {
IntStream.range(1, 10000)
.forEach(i -> items.add("Item-" + i));
}
B. 메모리/리소스 누수 (Memory Leak)
사용 후 닫아야 하는 자원을 방치하여 시스템 자원(FD)과 객체가 해제되지 않는 케이스이다.
@GetMapping("/file-read")
public void readFile() throws IOException {
FileInputStream fileInputStream = new FileInputStream("./file.txt");
for (int i = 0; i < 3; i++) {
byte[] bytes = fileInputStream.readNBytes(2000);
}
}
위의 엔드포인트들로 여러 차례 요청을 보내 메모리 부하를 일으킨 뒤, 분석을 위한 덤프 파일을 추출한다.
덤프를 생성하는 방법은 여러 가지가 있지만, 여기서는 가장 표준적인 jcmd 명령어를 사용했다.
# jcmd를 이용한 힙 덤프 생성 예시
jcmd <PID> GC.heap_dump heapdump.hprof
(덤프를 추출하는 과정에서 Stop-The-World 같은 현상이 있을 수 있으니, 프로세스가 바쁘게 돌아가는 시점에서 덤프를 뜨는 것은 주의해야 한다)
.hprof 파일을 Intellij Profiler로 열면 방대한 객체들의 목록이 펼쳐진다.

여기서 우리가 가장 먼저 주목해야 할 곳은 상단의 클래스/집계/얕음/유지 항목이다.
얕음(Shallow) vs 유지(Retained): 무엇을 봐야 할까?
메모리 분석의 중요한 부분이라고 생각된다.
- 얕은 크기(Shallow Size): 객체 본인이 가진 순수 무게이다. 예를 들어, ArrayList 자체의 크기일 뿐 그 안에 담긴 수만 개의 데이터 무게는 포함하지 않는다.
- 유지된 크기(Retained Size): 이 글의 핵심이다. "이 객체가 사라질 때 함께 해제될 수 있는 전체 메모리"를 뜻한다. 진짜 범인은 몸집은 작더라도, 주머니에 수만개의 데이터를 넣고 안 놔주는 녀석이기 때문이다.
메모리 추적의 두 가지 경로
어디서 메모리가 새고 있는지 확인하기 위해, 필자는 두 가지 분석 방식을 병행한다.
1. Bottom-up 방식: "큰 객체로부터 거꾸로 올라가기"
가장 점유율이 높은 '무거운 객체'를 먼저 찾고, 그 객체를 누가 소유하고 있는지 상위 계층으로 거슬러 올라가 어디서 해당 객체가 생성되었는지 파악하는 방식이다.

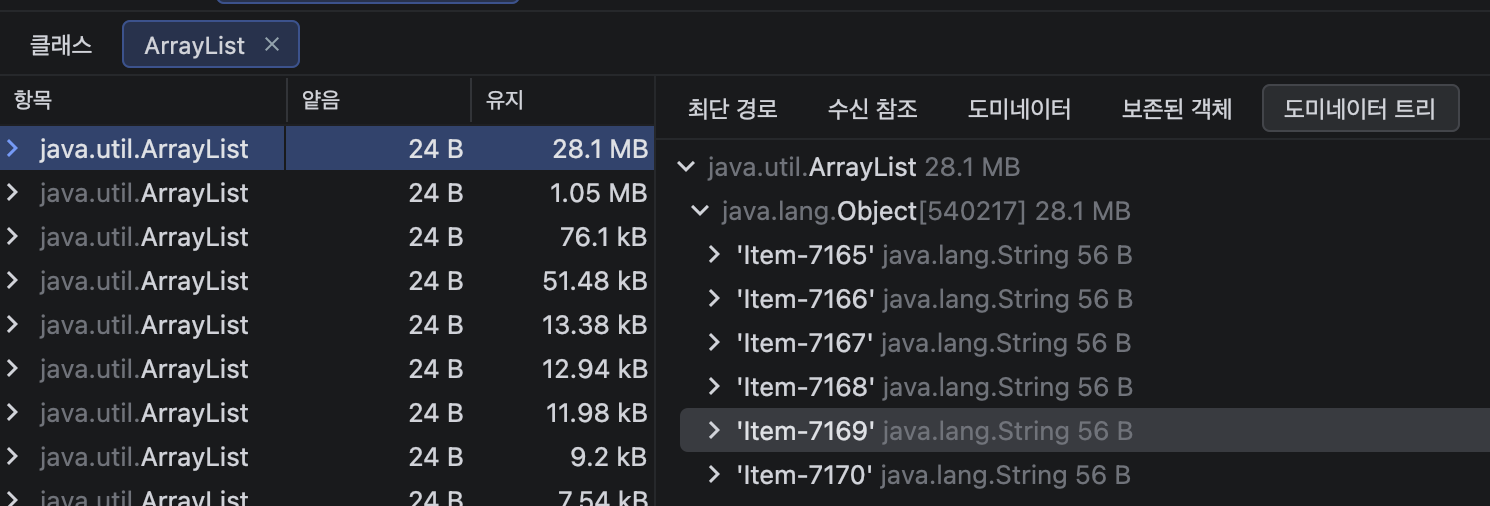
- 분석 결과: 특정 ArrayList가 28.1 MB를 점유하고 있음을 확인했고, 추적 결과 com.seonghyeon.demo12.controller.TestController 필드에 연결되어 있음을 지목할 수 있다.
- 도미네이터 트리: 이 기능을 활용하면 객체 간의 지배 관계를 시각화하여, 어떤 루트 객체가 메모리를 독점하고 있는지 한눈에 파악할 수 있다.
2. Top-down 방식: "의심되는 곳부터 파헤치기"
우리 서비스의 패키지(com.seonghyeon.*)를 먼저 필터링한 뒤, 우리가 짠 코드 중 어떤 객체가 비정상적으로 비대했는지 내려다보는 방식이다.

번외: 프로파일러가 놓치기 쉬운 '범인', 파일 디스크립터(FD)
때로는 힙 메모리 지표는 정상인데 서버가 죽는 경우, 또는 지표상으로 메모리 사용량이 완만하게 우상향하는 매트릭이 관찰될 때가 있다.
이는 InputStream 같은 리소스를 열기만 하고 닫지 않았을 때 주로 발생한다.
이때는 힙 덤프보다 먼저 프로세스가 관리하는 파일 디스크립터(FD)를 확인해보는 것이 좋다.
OS 레벨에서 해당 프로세스가 비정상적으로 많은 FD 번호표를 쥐고 있다면, 그것이 바로 리소스 누수의 증거가 된다.
위에서 작성한 메모리 누수 코드가 FD를 확인했을 때 어떤 결과가 나오는지 확인해보자.
1. 현재 프로세스가 점유한 FD 개수 확인
먼저, 우리 프로세스가 얼마나 많은 파일과 소켓을 물고 있는지 개수를 세어보자.
$ lsof -p {pid} | wc -l
# 결과: 110 (정상 범위는 서비스 규모마다 다르지만, 비정상적으로 높다면 주의)
FD 점유가 위험한 이유
FD는 단순히 파일 읽기에만 쓰이지 않는다. DB 커넥션, HTTP 커넥션 등 모든 네트워크 연결이 FD를 소모한다.
따라서 FD가 고갈되면 서버는 외부와의 모든 통신 통로가 막히는 '고립상태'가 된다.
2. OS가 허용한 한계치(Limit) 확인
개수만 봐서는 누수인지, 사용자가 많거나 DB Connection이 많은지 알수 없다.
OS가 정해놓은 한계치가 얼마인지 대조해보자.
$ ulimit -n
# 결과: 14848 (보통 1024~65535 사이로 설정)(만약 한계에 근접한 FD 개수를 사용하고있다면 이를 CRITICAL 수준으로 검토해야 한다)
3. 실제 FD 정보를 확인 (메모리 누수를 직접 확인)
$ lsof -p {pid}
결과:
~~
java 67812 REG 58935718 /Users/name/workspace/demo12/file.txt
java 67812 REG 58935718 /Users/name/workspace/demo12/file.txt
...
java 67812 REG 58935718 /Users/name/workspace/demo12/file.txt
위 결과처럼 동일한 파일 이름이 서로 다른 FD 번호를 달고 수백 줄씩 잡혀 있다면, 100% 리소스 누수이다.
InputStream을 열고 제때 close()하지 않아 OS 자원을 계속 점유하고 있는 상황인 것이다.
한단계만 더 들어가보자.
리눅스에서 파일을 지웠는데 디스크 용량이 복구되지 않는 경험이 있다면, 이 역시 FD 때문일 수 있다.
파일은 삭제되었으나, FD로 인해 디스크에서 용량이 해제 및 반환되지 않는 경우일 수 있다.
(설정 파일을 모르고 지웠고, 정상적으로 돌던 서비스가 일주일 뒤 단순 재기동에 실패하는 경우가 이런경우다)
이런 경우 lsof 명령어를 통해 해당 파일이 FD로써 사용되고 있는지 파악할 수 있다.
(연결된 FD가 없을때만 삭제하는 것을 권장한다.)
$ lsof file.txt
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 67812 yuseonghyeon 71r REG 1,14 26963 58935718 file.txt
java 67812 yuseonghyeon 76r REG 1,14 26963 58935718 file.txt
...
2. 스레드 덤프(Thread Dump): 텍스트 속 '병목'의 현장 검거
스레드 덤프는 JVM 내 모든 스레드의 현재 상태를 기록한다. CPU 점유율 폭증이나 응답 지연 시 필수로 사용해야 한다.
A. 데드락 (DeadLock)
lockAToB 에서는 lockA 모니터락을 걸고 lockB를 요청한다.
lockBToA 에서는 lockB 모니터락을 걸고 lockA를 요청하면서 데드락이 발생한다.
private final Object lockA = new Object();
private final Object lockB = new Object();
@GetMapping("/lock-a-to-b")
public void lockAToB() {
synchronized (lockA) {
sleepTwoSeconds();
synchronized (lockB) {
sleepTwoSeconds();
}
}
}
@GetMapping("/lock-b-to-a")
public void lockBToA() {
synchronized (lockB) {
sleepTwoSeconds();
synchronized (lockA) {
sleepTwoSeconds();
}
}
}
B. 무한 재귀 (Recursion)
@GetMapping("/recursion")
public void recursion() {
sleepTwoSeconds();
recursion();
}
위의 엔드포인트들로 요청을 보내 문제를 발생시킨 뒤, 분석을 위한 덤프 파일을 추출한다.
덤프를 생성하는 방법은 여러 가지가 있지만, 여기서는 가장 표준적인 jcmd 명령어를 사용했다.
# jcmd를 이용한 스레드 덤프 생성 예시
$ jcmd {pid} Thread.print > threads.txt
텍스트에 쓰여진 값들을 직접 확인하는 방법도 존재하나, 우아하게 Intellij Profiler를 활용해서 분석을 해보자.
Intellij 에서 상단 탭 [코드] -> [스택 추적 또는 스레드 덤프 분석...] 을 선택하고, txt 내부에 있던 값들을 모두 붙여넣고 분석을 시작한다.
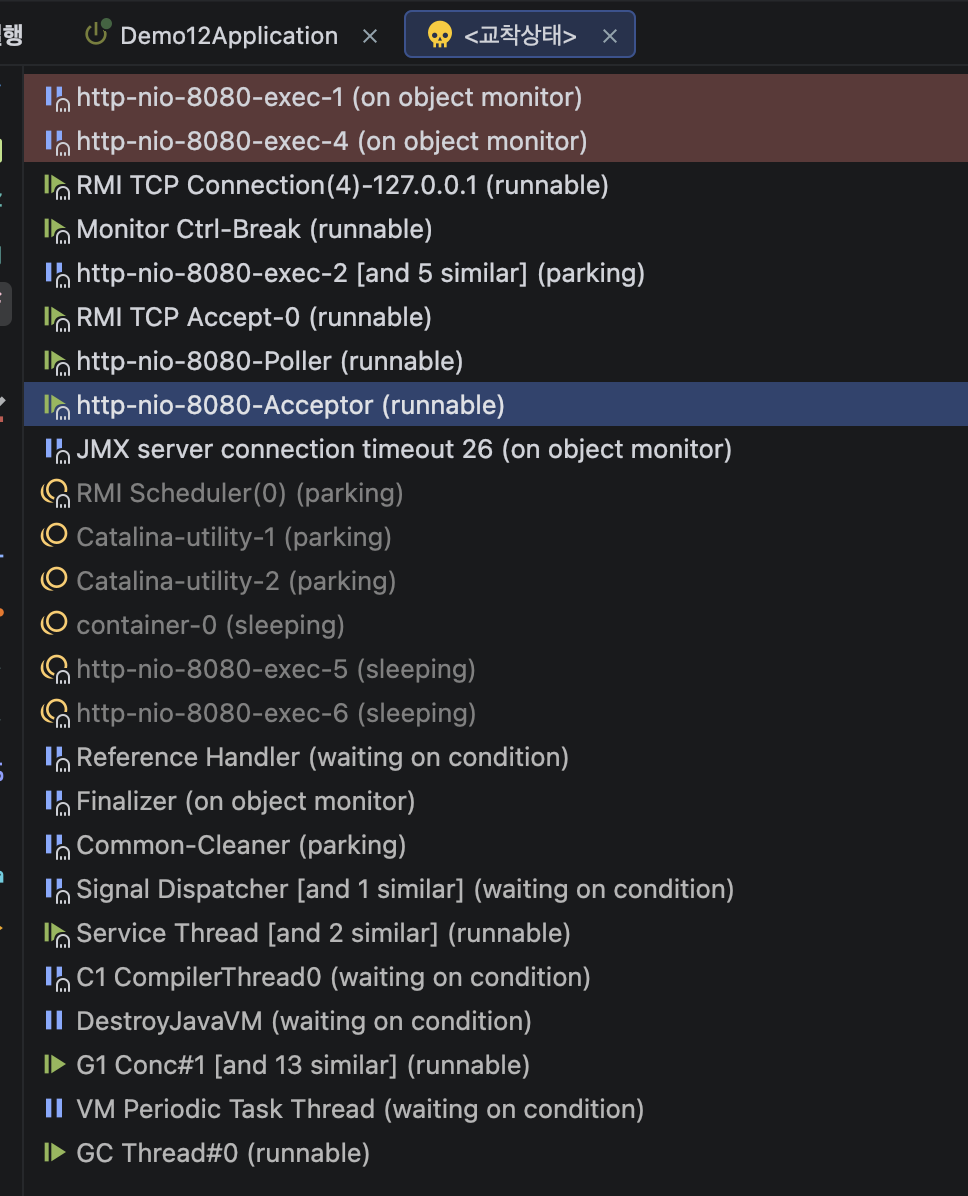
Intellij Profiler를 확인해보면, 데드락도 바로 표시가 되고 모든 스레드들을 확인해볼 수 있다.
스레드 덤프 문법 (Example: RMI TCP Accept-0)
먼저 TCP Accept를 하는 정상적인 스레드로 스레드 덤프 데이터를 읽는 방법을 알아보자.

- 첫째 줄 (상세 정보): 스레드 이름, 우선순위, CPU 점유 시간 등이 나온다.
- 둘째 줄 (상태): RUNNABLE, BLOCKED, WAITING 등 현재 스레드의 상태가 표시된다.
- 셋째 줄 이하 (콜 스택): 상단이 현재 위치. 아래에서 위로 호출되어 올라온 경로를 보여준다.
그러면 이를 토대로 장애 상황 분석에 대입해보자.
데드락 분석
두 스레드가 서로의 자원을 기다리며 영원히 멈춘 상태이다.

http-nio-8080-exec-1 스레드를 가져왔다.
이에 대한 정보를 풀어보면 다음과 같다.
- elapsed(경과 시간) : 417.35초간 요청이 돌아가는 것을 확인할 수 있다.
- State: BLOCKED (on object monitor): 현재 스레드 상태는 병목과 함께 BLOCK임을 뜻한다.
- xxx.lockAToB: 스레드는 lockAToB 메서드를 invoke한 상태이다.
- waiting to lock ... 420: 내가 필요한 열쇠(lock)를 의미한다.
- locked ...410: 내가 갖은 열쇠(lock)를 의미한다.
무한 재귀 분석

TIMED_WAITING은 sleep() 메서드를 걸어서 보여지는 것이므로 넘어가자.
아까와 같이 콜스택이 쌓여 있는 것을 보면, recursion을 계속해서 호출하는 것을 확인할 수 있다.
3. 마치며
위에서 설명하지 않았지만, GC 튜닝 과정에서 GC 발생이 좀 늦어진다는 생각이 들 경우 Heap Dump에서 "누가 객체를 잡고 GC가 못 가져가게 하는가" 를 추적할 수 있다.
그 참조 고리의 끝에 보통 잘못 설계된 static 변수나 종료되지 않은 스레드 풀이 있을 수 있다.
Grafana 대시보드가 "서버가 아프다"는 신호를 준다면, 덤프 분석은 "어디가 어떻게 아픈지" 수술대를 올리는 과정이므로, 장애 분석 시 필요하다면 적극 활용하는 것이 좋다.
'테스트코드 & 정적분석' 카테고리의 다른 글
| [AI-Native] 테스트 전략: 개발자에서 설계자로의 전환 (0) | 2026.02.09 |
|---|---|
| Spring Boot 3.4+에서 @MockBean이 @MockitoBean으로 대체된 이유 (0) | 2026.01.18 |
| 테스트 코드 작성 2편 동시성 이슈와 외부 의존성 제어 (0) | 2025.12.23 |
| 테스트 코드 작성 1편 테스트가 고통스럽다면, 설계를 의심하라 (feat. POJO & Time) (0) | 2025.12.22 |
| 테스트 코드, '작동'을 넘어 '지속 가능한 시스템'으로 (0) | 2025.12.22 |